Ответы на курс: Основы математической статистики
Пусть  , где случайная величина
, где случайная величина  имеет стандартное нормальное распределение
имеет стандартное нормальное распределение 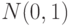 , а случайная величина
, а случайная величина  имеет распределение хи-квадрат с двумя степенями свободы (
имеет распределение хи-квадрат с двумя степенями свободы ( ). Известно, что и независимы. Какое распределение имеет случайная величина
). Известно, что и независимы. Какое распределение имеет случайная величина  ?
?
Предположение о том, что математическое ожидание некоторой случайной величины меньше нуля, следует считать:
Известно, что функция распределения  некоторой дискретной случайной величины принимает значение 0.8 при
некоторой дискретной случайной величины принимает значение 0.8 при  . Чему равна 0.8-квантиль этого распределения?
. Чему равна 0.8-квантиль этого распределения?
Предположение о том, что в этом году магистры первого курса факультета БИ имеют более высокую математическую подготовку чем магистры первого курса прошлого года, следует считать:
Независимые случайные величины  имеют стандартное нормальное распределение. Какое распределение имеет случайная величина
имеют стандартное нормальное распределение. Какое распределение имеет случайная величина  ?
?
Квантиль уровня 0.9 для распределения Стьюдента с 5-ю степенями свободы равна 1.476. Чему равна квантиль уровня 0.1 для этого распределения?
Независимые случайные величины 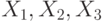 имеют стандартное нормальное. Какое распределение имеет случайная величина
имеют стандартное нормальное. Какое распределение имеет случайная величина  ?
?
Квантиль уровня 0.95 для распределения Стьюдента с 6-ю степенями свободы равна 1.943. Чему равна квантиль уровня 0.05 для этого распределения?
Предположение о том, что дисперсия некоторой случайной величины больше единицы, следует считать:
Случайная величина распределена равномерно на интервале (10;20). Чему равна 0.75-квантиль этой величины?
Квантиль уровня 0.975 для распределения Стьюдента с 10-ю степенями свободы равна 2.228. Чему равна квантиль уровня 0.025 для этого распределения?
Известно, что функция распределения некоторой дискретной случайной величины принимает значение 0.9 при  . Чему равна 0.9-квантиль этого распределения?
. Чему равна 0.9-квантиль этого распределения?
Известно, что функция распределения некоторой дискретной случайной величины принимает значение 0.7 при  . Чему равна 0.7-квантиль этого распределения?
. Чему равна 0.7-квантиль этого распределения?
Случайные величины и независимы, 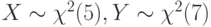 . Какое распределение имеет случайная величина
. Какое распределение имеет случайная величина  ?
?
Независимые случайные величины  имеют стандартное нормальное распределение. Какое распределение имеет случайная величина
имеют стандартное нормальное распределение. Какое распределение имеет случайная величина 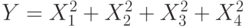 ?
?
Пусть 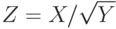 , где случайная величина имеет стандартное нормальное распределение , а случайная величина имеет распределение хи-квадрат с одной степенью свободы (
, где случайная величина имеет стандартное нормальное распределение , а случайная величина имеет распределение хи-квадрат с одной степенью свободы ( ). Известно, что и независимы. Какое распределение имеет случайная величина ?
). Известно, что и независимы. Какое распределение имеет случайная величина ?
Случайная величина распределена равномерно на интервале (10;20). Чему равна 0.8-квантиль этой величины?
По выборке  из распределения
из распределения  требуется проверить гипотезу о том, что неизвестный параметр
требуется проверить гипотезу о том, что неизвестный параметр  равен 5 против альтернативы о том, что значение параметра больше 5. Для проверки этой гипотезы применяется некоторый состоятельный критерий. Уровень значимости этого критерия равен 0.05. Функция мощности этого критерия в точке 6 можетпринимать значение:
равен 5 против альтернативы о том, что значение параметра больше 5. Для проверки этой гипотезы применяется некоторый состоятельный критерий. Уровень значимости этого критерия равен 0.05. Функция мощности этого критерия в точке 6 можетпринимать значение:
Проверяется параметрическая гипотеза  против альтернативной гипотезы
против альтернативной гипотезы 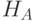 . Вид альтернативной гипотезы определяет
. Вид альтернативной гипотезы определяет
Вероятностью ошибки второго рода называют:
В некотором регионе А произошло 632 ДТП, из них 142 ДТП произошли по вине женщин-водителей. Известно, что 30 % водителей в регионе А — женщины. Можно ли считать, опираясь на приведенные данные, что женщины являются более аккуратными водителями чем мужчины. Пусть 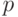 — доля женщин-нарушителей. Сформулируйте основную (проверяемую) гипотезу
— доля женщин-нарушителей. Сформулируйте основную (проверяемую) гипотезу в этой задаче.
в этой задаче.
Уровень значимости критерия обычно полагают равным:
По выборке из распределения требуется проверить гипотезу о том, что неизвестный параметр равен 5 против альтернативы о том, что значение параметра больше 5. Для проверки этой гипотезы применяется некоторый состоятельный критерий. Уровень значимости этого критерия равен 0.05. Чему равна функция мощности этого критерия в точке 5?
Для того чтобы сравнить два параметрических критерия, проверяющих гипотезу против альтернативы , достаточно знать
Вероятностью ошибки первого рода называют:
Если увеличить уровень значимости статистического критерия, то размер критической области при этом:
Для того, чтобы построить доверительную и критическую области критерия, проверяющего простую параметрическую гипотезу против сложной альтернативной гипотезы, необходимо знать:
Уровень значимости критерия равен 0.05. Чему равна вероятность того, что основная гипотеза будет справедливо принята?
Лемма Неймана-Пирсона дает правило построения наиболее мощного критерия для проверки:
Монету подбросили 600 раз, «орел» при этом появился 325 раз. Требуется проверить, опираясь на эти данные, что монета является симметричной. Пусть — вероятность выпадения «орла». Сформулируйте основную (проверяемую) гипотезу в этой задаче.
Считается, что партия изделий удовлетворяет ГОСТу, если в ней содержится не более 5% бракованных изделий. Из большой партии деталей для выборочного контроля случайным образом отобрали 100 деталей. Среди этих деталей обнаружили 6 бракованных деталей. Требуется принять решение о соответствии этой партии ГОСТу.
Обозначим долю бракованных деталей — . Сформулируйте альтернативную гипотезу  .
.
В некотором регионе была сформирована репрезентативная выборка и проведен социологический опрос по оцениванию вероятности p поддержки избирателями некоторой партии на ближайших выборах. Затем было решено уменьшить погрешность оценивания в 3 раза. Как изменится объем репрезентативной выборки?
В некотором регионе была сформирована репрезентативная выборка и проведен социологический опрос по оцениванию вероятности p поддержки избирателями некоторой партии на ближайших выборах. Затем было решено уменьшить погрешность оценивания в 2 раза. Как изменится объем репрезентативной выборки?
Известно, что генеральная совокупность неоднородна и представляется в виде двух слоев (например, проживающие в городской и в сельской местности) с весовыми коэффициентами 0.6 и 0.4 . Репрезентативная выборка должна быть сформирована следующим образом.
В ходе социологического опроса требуется оценить вероятность положительного ответа на некоторый вопрос с точностью до 0.01. Каков при этом должен быть примерный объем репрезентативной выборки?
Из генеральной совокупности большого объема производят выбор n респондентов с возвращением. Пусть случайная величина — количество респондентов, давших положительный ответ на вопрос, интересующий социолога. Какое распределение имеет случайная величина ?
Проводится социологический опрос по однородной генеральной совокупности, целью которого является оценивание вероятности p некоторого события (например, поддержки на выборах политической партии N). По предварительным данным эта вероятность заключена в интервале (0.6; 0.7). Какое значение вероятности p следует подставить в формулу, определяющую размер генеральной совокупности?
В ходе социологического опроса требуется оценить вероятность положительного ответа на некоторый вопрос с точностью до 0.05. Каков при этом должен быть примерный объем репрезентативной выборки?
Известно, что генеральная совокупность неоднородна и представляется в виде двух слоев (например, имеющие высшее образование и не имеющие высшего образования) с весовыми коэффициентами 0.2 и 0.8. Репрезентативная выборка должна быть сформирована следующим образом.
Проводится социологический опрос по однородной генеральной совокупности, целью которого является оценивание вероятности p некоторого события (например, поддержки на выборах политической партии N). По предварительным данным эта вероятность заключена в интервале (0.3; 0.4). Какое значение вероятности p следует подставить в формулу, определяющую размер генеральной совокупности?
В некотором регионе была сформирована репрезентативная выборка и проведен социологический опрос по оцениванию вероятности p поддержки избирателями некоторой партии на ближайших выборах. Затем было решено уменьшить погрешность оценивания в 4 раза. Как изменится объем репрезентативной выборки?
При проведении социологических опросов необходимо осуществлять выбор без возвращения в следующих ситуациях:
В ходе социологического опроса было опрошено  респондентов, из них респондентов дали положительный ответ на вопрос, заданный социологом. Социолог оценивает вероятность p положительного ответа на свой вопрос следующим образом
респондентов, из них респондентов дали положительный ответ на вопрос, заданный социологом. Социолог оценивает вероятность p положительного ответа на свой вопрос следующим образом  . Какими свойствами обладает оценка
. Какими свойствами обладает оценка 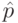 ?
?
Проводится социологический опрос по однородной генеральной совокупности, целью которого является оценивание вероятности p некоторого события (например, поддержки на выборах политической партии N). По предварительным данным эта вероятность заключена в интервале (0.45; 0.6). Какое значение вероятности p следует подставить в формулу, определяющую размер генеральной совокупности?
В ходе социологического опроса требуется оценить вероятность положительного ответа на некоторый вопрос с точностью до 0.025. Каков при этом должен быть примерный объем репрезентативной выборки?
Из генеральной совокупности производят выбор n респондентов без возвращения. Пусть случайная величина — количество респондентов, давших положительный ответ на вопрос, интересующий социолога. Какое распределение имеет случайная величина ?
Рассматривается модель  . Какие из следующих статистик являются центральными статистиками для
. Какие из следующих статистик являются центральными статистиками для  ?
?
Дана следующая реализация выборки: 5; 1; 4; 7; 6; 4; 10. Какой ранг имеет третье наблюдение этой выборки?
Дана следующая реализация выборки: -2; 0;1;3; -1;-1; 1; 2; 0.5; 1.5; 1;-3; 1. Какой ранг имеет третье наблюдение этой выборки?
Имеются две гауссовские выборки одинакового объема. Известно, что дисперсия первой выборки равна 1, а дисперсия второй выборки равна 4. По каждой из выборок построен доверительный интервал уровня надежности 0.95. Как соотносятся длины постоенных интервалов?
По выборке построены доверительные интервалы уровня надежности  для параметра
для параметра 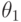 .Обозначим
.Обозначим  — выборочную дисперсию, а
— выборочную дисперсию, а  -квантиль уровня
-квантиль уровня 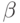 распределения Стьюдента с степенями свободы. Какой из представленных интервалов является центральным доверительным интервалом параметра ?
распределения Стьюдента с степенями свободы. Какой из представленных интервалов является центральным доверительным интервалом параметра ?
Рассматриваются две независимые гауссовские выборки 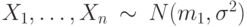 и
и  . Параметры
. Параметры  и
и  неизвестны. Обозначим
неизвестны. Обозначим  . Какое распределение имеет статистика
. Какое распределение имеет статистика 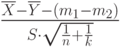 ?
?
Рассматриваются две независимые гауссовские выборки и  . Параметры неизвестны, — известно. Какое распределение имеет статистика
. Параметры неизвестны, — известно. Какое распределение имеет статистика 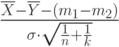 ?
?
По выборке  с известной дисперсией построены доверительные интервалы уровня надежности для параметра . Обозначим
с известной дисперсией построены доверительные интервалы уровня надежности для параметра . Обозначим  — квантиль стандартного гауссовского распределения уровня . Какой из представленных интервалов является центральным доверительным интервалом параметра ?
— квантиль стандартного гауссовского распределения уровня . Какой из представленных интервалов является центральным доверительным интервалом параметра ?
По выборке  с известным математическим ожиданием
с известным математическим ожиданием 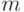 построены доверительные интервалы уровня надежности для параметра
построены доверительные интервалы уровня надежности для параметра  .Обозначим
.Обозначим 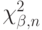 — квантиль уровня распределения хи-квадрат с степенями свободы. Какой из представленных интервалов является центральным доверительным интервалом параметра ?
— квантиль уровня распределения хи-квадрат с степенями свободы. Какой из представленных интервалов является центральным доверительным интервалом параметра ?
Выборка  , а выборка
, а выборка  имеет равномерное распределение
имеет равномерное распределение 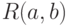 . В каком случае эти выборки будут являться однородными?
. В каком случае эти выборки будут являться однородными?
Рассматривается модель  . Какие из следующих статистик являются центральными статистиками для ?
. Какие из следующих статистик являются центральными статистиками для ?
Рассматриваются две независимые гауссовские выборки  и
и 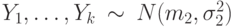 . Параметры
. Параметры  неизвестны. Пусть
неизвестны. Пусть 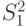 -выборочная дисперсия первой выборки,
-выборочная дисперсия первой выборки, 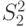 -выборочная дисперсия второй выборки. Какое распределение имеет статистика
-выборочная дисперсия второй выборки. Какое распределение имеет статистика  в случае, когда дисперсии первой и второй выборок одинаковы?
в случае, когда дисперсии первой и второй выборок одинаковы?
Имеются две гауссовские выборки и  . В каком случае эти выборки будут являться однородными?
. В каком случае эти выборки будут являться однородными?
Дана следующая реализация выборки: 6; 2; 8;10;8; 6; 4; 8; 9. Какой ранг имеет третье наблюдение этой выборки?
Рассматривается модель независимых случайных величин . Какие из следующих статистик являются центральными статистиками для ?
По выборке из гауссовского распределения с известной дисперсией построены доверительные интервалы для неизвестного математического ожидания уровня надежности 0.95 и уровня надежности 0.99. Как соотносятся длины построенных интервалов?
По выборке  построена оценка неизвестного математического ожидания
построена оценка неизвестного математического ожидания  . Для этой оценки справедливы следующие утверждения:
. Для этой оценки справедливы следующие утверждения:
Пусть имеются две независимые гауссовские выборки и  . Проверяется гипотеза
. Проверяется гипотеза  . Для проверки этой гипотезы применяют критерий Вилкоксона и критерий Стьюдента. Чему равна АОЭ (асимптотическая относительная эффективность) по Питмену критерия Вилкоксона по отношению к критерию Стьюдента?
. Для проверки этой гипотезы применяют критерий Вилкоксона и критерий Стьюдента. Чему равна АОЭ (асимптотическая относительная эффективность) по Питмену критерия Вилкоксона по отношению к критерию Стьюдента?
Пусть выборка 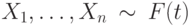 , а выборка
, а выборка  . Для проверки гипотезы
. Для проверки гипотезы  применяют критерий Вилкоксона и критерий Стьюдента. Известно, что распределение
применяют критерий Вилкоксона и критерий Стьюдента. Известно, что распределение  — непрерывное распределение с нулевой медианой. Чему равна нижняя граница
— непрерывное распределение с нулевой медианой. Чему равна нижняя граница  АОЭ (асимптотической относительной эффективности) по Питмену критерия Вилкоксона по отношению к критерию Стьюдента?
АОЭ (асимптотической относительной эффективности) по Питмену критерия Вилкоксона по отношению к критерию Стьюдента?
Квантиль уровня 0.99 статистики Вилкоксона при объемах выборок 8 (объем первой выборки) и 7 (объем второй выборки) равна 76 (W(8;7;0.99) =76). Чему равна квантиль W(8;7;0.01)?
Эмпирическая функция распределения выборки является состоятельной оценкой для:
У нескольких деталей, изготовленных на токарном станке, измерено отклонение размера детали от контрольного размера. Затем была произведена наладка станка. После наладки было подвергнуто контролю еще несколько деталей. Требуется выяснить, привела ли наладка станка к увеличению точности изготовления деталей. Какой (какие) из перечисленных критериев позволяет решить данную задачу?
Какое распределение имеет статистика Колмогорова-Смирнова при большом количестве наблюдений?
К недостаткам ранговых критериев следует отнести:
Квантиль уровня 0.99 статистики Вилкоксона при объемах выборок 10 (объем первой выборки) и 8 (объем второй выборки) равна 102 (W(10;8;0.99) = 102). Чему равна квантиль W(10;8;0.01)?
Пусть выборка 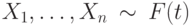 , а выборка . Для проверки гипотезы применяют критерий Вилкоксона и критерий Стьюдента. Известно, что распределение -это распределение Тьюки («загрязненное» нормальное распределение) с параметром «загрязнения» равным 0.05. АОЭ (асимптотическая относительная эффективность) по Питмену критерия Вилкоксона по отношению к критерию Стьюдента при описанных условиях будет:
, а выборка . Для проверки гипотезы применяют критерий Вилкоксона и критерий Стьюдента. Известно, что распределение -это распределение Тьюки («загрязненное» нормальное распределение) с параметром «загрязнения» равным 0.05. АОЭ (асимптотическая относительная эффективность) по Питмену критерия Вилкоксона по отношению к критерию Стьюдента при описанных условиях будет:
Квантиль уровня 0.99 статистики Вилкоксона при объемах выборок 10 (объем первой выборки) и 5 (объем второй выборки) равна 59 (W(10;5;0.99) = 59). Чему равна квантиль W(10;5;0.01)?
У нескольких деталей, изготовленных на токарном станке, измерено отклонение размера детали от контрольного размера. Затем была произведена наладка станка. После наладки было подвергнуто контролю еще несколько деталей. Требуется выяснить, привела ли наладка станка к увеличению точности изготовления деталей. Сделано предположение о том, что все наблюдения в задаче имеют гауссовское распределение. Какой (какие) из перечисленных критериев позволяет решить данную задачу?
Критерий Вилкоксона предназначен для проверки гипотезы об однородности двух выборок против альтернативы:
Случайная величина распределена равномерно на интервале (10;20). Чему равна 0.9-квантиль этой величины?
Известно, что генеральная совокупность неоднородна и представляется в виде двух слоев (например, пенсионеры и трудоспособное население) с весовыми коэффициентами 0.3 и 0.7 . Репрезентативная выборка должна быть сформирована следующим образом.
По выборке из гауссовского распределения с известной дисперсией строят доверительный интервал для неизвестного математического ожидания заданного уровня надежности. Как изменится длина доверительного интервала, если объем выборки увеличить в 4 раза?
Имеются данные о потребительских расходах на душу населения по всем областям двух соседних регионов. Необходимо выяснить, одинаковы ли в среднем потребительские расходы на душу населения в этих регионах? Какой (какие) из перечисленных критериев позволяет решить данную задачу?
Уровнем значимости критерия называют:
